データベースの代名詞となっているリレーショナルデータベース(RDB)というものがあります。
有名どころではMySQLやPostgreSQL、Oracle DBなどがこのRDBをアプリケーションとして実装したリレーショナルデーターベースマネージメントシステム(RDBMS)と呼ばれています。
ここ数年はNoSQLが台頭してきていますが、それぞれ得手不得手があり決してRDBの代替とは言えずRDBの活躍はまだまだ続きそうです。
そんなRDBの設計において重要な理論に正規化というものが存在します。
RDBを触り始めて間もない比較的駆け出しの人を対象に正規化の解説をしたいと思います。
正規化
RDBにおける正規化というのは一言で表すとデータの重複をなくす作業に当たります。
データの重複は更新時異常(=データ不整合)の原因になり基本的に避けるべきです。
いつぞや非正規形の方が見やすいし結合の必要がなくて効率的だから良いみたいな論調を見た記憶もありますが大きな間違いです。
正規化する事でOne Fact in One Placeを保ち、更新時異常を防ぎつつ、テーブルやカラムの意味も分かりやすくなります。
さらに1つのテーブルにさまざまなデータが入るとロックがかかった際の影響範囲が大きくなり結果としてパフォーマンスを下げることも考えられます。
※One Fact in One Place
直訳すると「1つの事実は1つの場所」です。
ようは同じデータをいろんな場所に重複しないようにしよう。という考え方です。
更新時異常
正規形の解説の前に更新時異常の例をあげます。
| 名前 | 住所 | 商品ID |
|---|---|---|
| 山本 太郎 | 東京都 | 001 |
| 山本 太郎 | 東京都 | 002 |
| 田中 一郎 | 神奈川県 | 001 |
こんな注文テーブルがあるとします。
名前とその人の住所と注文した商品IDがあるだけのシンプルなテーブルです。
ではこのテーブルで山本さんが千葉県に引っ越ししたとします。そうするとこのテーブルでは確実に山本さんの行全ての住所カラムのデータが更新される事が保証されていなければいけません。
| 名前 | 住所 | 商品ID |
|---|---|---|
| 山本 太郎 | 千葉県 | 001 |
| 山本 太郎 | 東京都 | 002 |
| 田中 一郎 | 神奈川県 | 001 |
こうなってしまわないように注意する必要があります。
このケースならWHERE句に「名前=’山本 太郎’」で大丈夫だろ?と思う方もいるかもしれませんがそれはテーブルすべてをロックできる場合位の話です。
ほぼ同タイミングで新たな注文が発生した場合に異常が発生する可能性がありますし、何よりプログラム側でこの点を考慮した実装が必要なってしまいます。
引っ越しと新規注文が同時に行われた場合は
| 名前 | 住所 | 商品ID | |
|---|---|---|---|
| 山本 太郎 | 千葉県 | 001 | ※住所変更処理 |
| 山本 太郎 | 千葉県 | 002 | ※住所変更処理 |
| 田中 一郎 | 神奈川県 | 001 | 無関係 |
| 山本 太郎 | 東京都 | 003 | ※同タイミングで新規注文が来た |
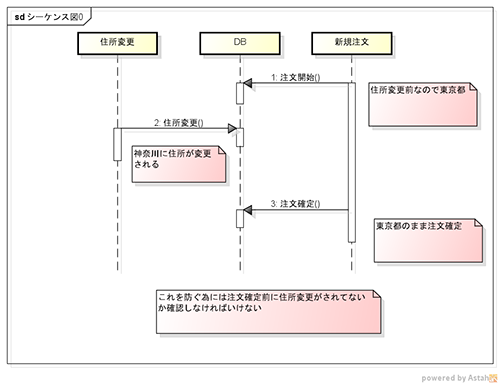
こういう困った事態を防ぐために正規化はあります。
正規化の種類
正規化にはいくらか種類があります。
- 第1正規形
- 第2正規形
- 第3正規形
- ボイスコッド正規形
- 第4正規形
- 第5正規形
- 第6正規形
の全7つです。
下の正規形は上の正規形の条件を満たしていなければいけません。第2正規形は必ず第1正規形も満たす必要があります。
そして、この中で第1~ボイスコッドまでの4つは必須です。というわけでこの記事ではその4つを簡単に解説します。
第4からは難しい上にボイスコッドまで正規化した際に自動的にそうなってる場合も多いので今回は割愛します。
※ボイスコッドも第3まで正規化すると満たしていることは多いですが……
第1正規形
第1正規形は大体繰り返しが無い状態というような説明がされています。
実際は
- 行に順序がない
- 列に順序がない
- 行に重複がない
- NULLがない
- データがATOMである
という条件です。
1~4は特に難しくないと思います。そのままの意味です。
5が繰り返しが無いという事に当たります。
ATOMであるというのはそのデータがそれ以上分割できないという意味です。件の本ではある集合の1要素であるという旨の解説がされていました。
なので、ある集合内の2つ以上の要素が1つのテーブルに含まれている場合はATOMでないと言えます。
その典型例が、1つのカラムに複数のデータが格納されているケースや、同じ集合からのデータを複数のカラムに分割して格納されているケースです。
例1)
| 名前 | 使用スキル |
|---|---|
| スライム | たいあたり |
| ゴブリン | なぐる,ける |
例2)
| 名前 | 使用スキル1 | 使用スキル2 |
|---|---|---|
| スライム | たいあたり | NULL |
| ゴブリン | なぐる | ける |
「ゴブリン」のスキルが例1では1つのカラムに2つ押し込められています。例2ではスキルのカラムを2つに分けてそれぞれ設定しています。
このようなケースはデータがATOMでない(1行が1つの事実を表していない)ので第1正規形違反です。
※ゴブリンはなぐるが使えるという事実とけるが使えるという事実の2つが1行存在しています。
これを「なぐるとけるが使える」という1つの事実と解釈した場合、スキルは「なぐる」と「ける」と「なぐるとける」という風に全ての組み合わせを網羅する必要が出てきます。
これはスキルという集合の中から2つを1つの行に押し込もうとしているために起こる問題です。
これは以下のようにすることで第1正規形を満たせます。
| 名前 | 使用スキル |
|---|---|
| スライム | たいあたり |
| ゴブリン | なぐる |
| ゴブリン | ける |
簡単ですね。
第2正規形
第2正規形は前述の第1を満たしているという前提で、部分関数従属性をなくします。
関数従属性
さて関数従属性というわかりにくい単語が出てきましたが、これ自体はそこまで難しいものではありません。
これはある集合Aと別の集合Bにおいて、集合Aの中から1つ適当に値を取り出すと、自動的に集合Bの中の値も1つ決まるような関係です。
ざっくりいうとAが分かればBも分かる(Bが分かってもAが分かるとは限らない)というものです。
例えば「ゲームソフト」と「発売日」という2つの集合があるとします。
ゲームソフトの集合から「splatoon」を取り出します。そうすると発売日という集合からは「2015年5月28日」というのが一意に決定されます。
逆がどうかというと、「2015年5月28日」からだと、「Project mirai でらっくす」や「サイコパス」などがあり得るので一意には決めることは出来ません。
候補キー
正規形を考える上で重要な考え方がこの候補キーです。
これはテーブルの中である行を一意に決定づけるための1つ以上で余計なものを含まないカラムの事です。
「一意に決定づける」というのは、たくさんある行の中から1行だけを検索して探し出すという事と思ってもらって大丈夫です。
上で例に出したテーブルではカラム名にアンダーラインを引いています。
候補キー以外のカラム達は非キー属性と呼ばれています。
部分関数従属性
以上2つを踏まえて部分関数従属性を解説すると、これは候補キーの中のいずれかのカラムと非キー属性が関数従属性を持っている場合の特別な場合の呼び方です。
ようやくすると候補キーが2つ以上のカラムで構成されていて、そのどれかが決まると、キーではないカラムが一意に決定されるという事ですね。
候補キーが単一カラムから構成される場合は部分関数従属性は存在しません。(部分じゃないので……)
第2正規形にするには
それでは具体的にどうやって第2正規形にするかです。
| ユーザー名 | 会得スキル | プレイ日数 |
|---|---|---|
| 山田 太郎 | たいあたり | 60 |
| 山田 太郎 | なぐる | 60 |
| 田中 一郎 | 回復 | 30 |
「山田 太郎」は「たいあたり」と「なぐる」というスキルを会得しており、プレイ日数は60日です。(最初に上げた引っ越しのテーブルと似たケースです。)
「田中 一郎」の方は「回復」スキルを会得し、プレイ日数30日です。
このようなテーブルでは候補キーは「ユーザー名」と「会得スキル」の2つになります。(1つの行を検索するには「ユーザー名」と「会得スキル」の2つの情報が必要ですね。)
そして、「ユーザー名」から「プレイ日数」への関数従属性が存在します。つまり、「ユーザー名」が分かれば「プレイ日数」が分かるという関係です。
候補キーの中の(全部ではなく)いずれかから非キー属性への関数従属性なので、これは部分関数従属性にあたります。
これをテーブルを分割して取り除きます。
| ユーザー名 | 会得スキル |
|---|---|
| 山田 太郎 | たいあたり |
| 山田 太郎 | なぐる |
| 田中 一郎 | 回復 |
| ユーザー名 | プレイ日数 |
|---|---|
| 山田 太郎 | 60 |
| 田中 一郎 | 30 |
こんな感じです。
第3正規形
第3は第2に加えて、推移関数従属性をなくします。
推移関数従属性
推移関数従属性は非キー属性から別の非キー属性への関数従属性です。
第3正規形にするには
| ユーザー名 | パートナー名 | パートナー効果 |
|---|---|---|
| 山田 太郎 | かーばんくるん | 自然回復力上昇 |
| 田中 一郎 | けつぁるこあとるん | 火が吹けるようになる |
| 佐藤 三郎 | けつぁるこあとるん | 火が吹けるようになる |
このテーブルでは「パートナー名」から「パートナー効果」への関数従属性が存在します。
つまり、「パートナー名」が分かれば「パートナー効果」が分かります。
これは非キーから別の非キーへの関数従属性なため、推移関数従属性です。
| ユーザー名 | パートナー名 |
|---|---|
| 山田 太郎 | かーばんくるん |
| 田中 一郎 | けつぁるこあとるん |
| 佐藤 三郎 | けつぁるこあとるん |
| パートナー名 | パートナー効果 |
|---|---|
| かーばんくるん | 自然回復力上昇 |
| けつぁるこあとるん | 火が吹けるようになる |
という感じでテーブルを分割できます。
「ユーザー名」から直接「パートナー効果」は導き出せませんが、「ユーザー名」→「パートナー名」→「パートナー効果」と導くことが出来ます。
ボイスコッド正規形
これは第3に加えて、非キー属性から候補キーの中のいずれかのカラムへの関数従属性を取り除いた状態です。
実際問題多くの場合は第3まで正規化されていると結果としてボイスコッドの条件を満たしている場合が多いです。(これを踏まえて、第3までで良いと解説するサイトも見かけます。)
というよりも、第3まで正規化しているのに、ボイスコッドを満たしていない場合は候補キーの選択が間違っている可能性が高いです。
もし、非キー属性が決まれば、候補キーが決まるようなケースになっている場合は一度非正規形に戻し、もう一度正規化を考え直してみてください。
例えば以下のような例です。
| ユーザー名 | クラス | ジョブ |
|---|---|---|
| 山田 太郎 | アタッカー | モンク |
| 山田 太郎 | ヒーラー | 医者 |
| 田中 一郎 | ヒーラー | 僧侶 |
| 田中 一郎 | サポーター | 遊び人 |
| 佐藤 次郎吉 | アタッカー | モンク |
このゲームでは各ユーザーごとに複数のクラスを選択できて、かつ各クラスでは複数あるジョブのウチ1つを選択できるという仕様のようです。
このテーブルでは非キーである「ジョブ」から候補キーの中のカラムである「クラス」への関数従属性が存在します。
これを先ほどの第3正規形と同じような手順でテーブルを分けると(推移関数従属性がないけども)
| ユーザー名 | クラス |
|---|---|
| 山田 太郎 | アタッカー |
| 山田 太郎 | ヒーラー |
| 田中 一郎 | ヒーラー |
| 田中 一郎 | サポーター |
| 佐藤 次郎吉 | アタッカー |
| クラス | ジョブ |
|---|---|
| アタッカー | モンク |
| ヒーラー | 医者 |
| ヒーラー | 僧侶 |
| サポーター | 遊び人 |
となります。
しかしこれをよく見ればわかりますが、元のテーブルに戻せません。
ヒーラーが医者なのか僧侶なのかわかりません。たしかに{ユーザー名,クラス名}の組み合わせは候補キーなのですが、この場合は{ユーザー名,ジョブ}の方がキーとして利用するには適当です。
| ユーザー名 | ジョブ |
|---|---|
| 山田 太郎 | モンク |
| 山田 太郎 | 医者 |
| 田中 一郎 | 僧侶 |
| 田中 一郎 | 遊び人 |
| 佐藤 次郎吉 | モンク |
| ジョブ | クラス |
|---|---|
| モンク | アタッカー |
| 医者 | ヒーラー |
| 僧侶 | ヒーラー |
| 遊び人 | サポーター |
ボイスコッド正規形は候補キーが複数ある際の選択が本当にあっているかの指標になります。
正規化は慣れ
正規化は慣れれば結構サクサクできるようになります。
ただ、やっぱり理屈は重要で理屈がわからなかったらおざなりな設計になりがちだと思います。
このページではかなり砕きましたし、わかりやすさの為に単語を置き換えたりもしています。
